Web Crawler and Web Scraper are both tools used for extracting information from websites, but they serve different purposes and have distinct functionalities.
What is a Web Crawler:
A web crawler, also known as a spider or a bot, is an automated script or program that systematically browses the internet and visits web pages in order to gather data and build an index of the web. It follows hyperlinks from one page to another, recursively visiting and indexing as many pages as possible. The main purpose of a web crawler is to discover and retrieve web content for indexing by search engines. Crawlers are used by search engines like Google to create their search index, which enables users to find relevant information quickly. Websites that don’t wish to be crawled or found by search engines can use tools like the robots.txt file to request bots not index a website or only index portions of it.
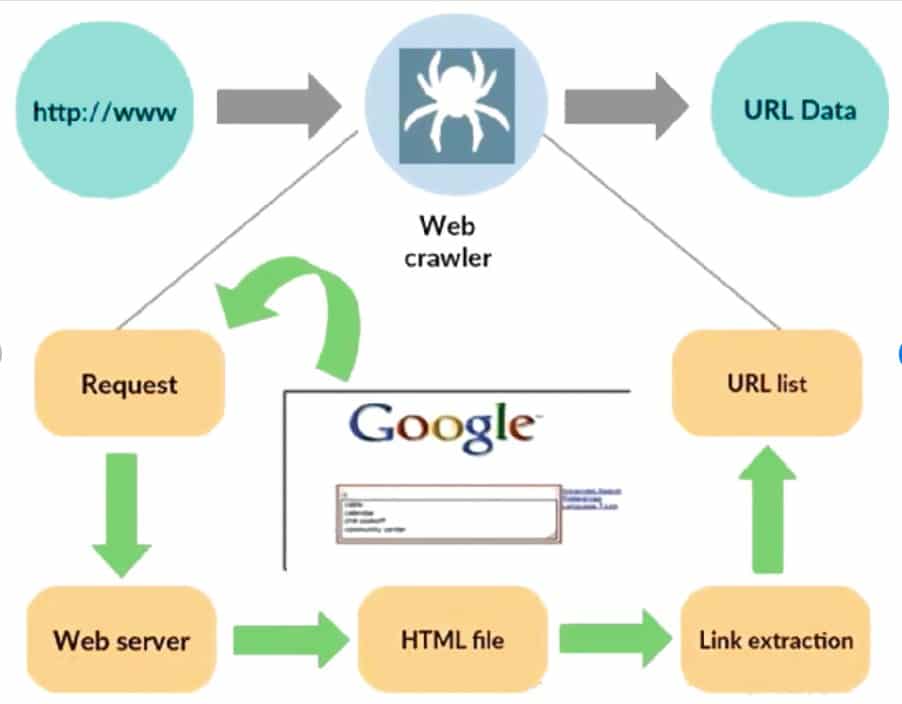
All popular search engines have their own crawlers that use a specific method when gathering information about webpages:
- Amazonbot is the Amazon web crawler.
- Bingbot is Microsoft’s search engine crawler for Bing.
- DuckDuckBot is the crawler for the search engine DuckDuckGo.
- Googlebot is the crawler for Google’s search engine.
- Yahoo Slurp is the crawler for Yahoo’s search engine.
- Yandex Bot is the crawler for the Yandex search engine.
What should you use a web crawler:
- Gather data for business intelligence
- Market research about the product or service you are offering
- Gather user behavior data to make your product perform better
- Simply make your product more SEO relevant with more content
What is a Web Scraper:
A web scraper is a tool like Zenrows, or a program that extracts specific data from websites by parsing and analyzing the underlying HTML or XML code of web pages.. Unlike web crawlers, web scrapers are designed to target and extract specific information from websites, such as product details, pricing information, news articles, or any other structured data. Web scrapers simulate human interaction with a website, navigating through web pages, locating desired elements, and extracting the required data. They can extract data from multiple pages or websites and save it in a structured format, such as a spreadsheet or a database.
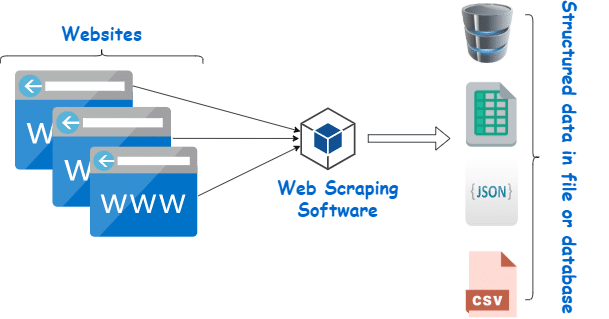
Web Scrapers can be divided on the basis of many different criteria, including
- Self-built that require advanced programming skills
- Pre-built Web Scrapers that you can download and customize them so they suit your purpose
- Browser extension that you can add to the browsewr you are using making them extremely easy to use but have limited capabilities
- Software Web Scrapers that you need to download and install them on your PC
- Cloud or Local Web Scrapers
What should you use a web crawler:
- Price Monitoring
- Market Research
- News Monitoring
- Sentiment Analysis
- Email Marketing
To summarize:
– Web crawlers are used to explore and index the web by following links and collecting data from various web pages.
– Web scrapers are used to extract specific data from websites by parsing and analyzing HTML or XML code.
While both web crawlers and web scrapers can be used to gather data from websites, their primary functions and approaches differ. Web crawlers focus on discovery and indexing, whereas web scrapers target and extract specific information.