What Is a Proxy Pool? How It Works and Why It Matters

If you’ve tried running a large-scale web scraping operation or managing anonymous browsing at scale, you’ve likely hit IP bans or rate limits fast. Understanding what is a proxy pool, and more specifically how proxy pool quality and rotation strategy affect real-world outcomes, is where most guides stop short. This article covers how proxy pools work from the architecture level down, why pool management matters more than raw IP count, which proxy types suit which use cases, and how to apply them correctly for scraping, testing, and anonymity workflows.
Table of Contents
- Key Takeaways
- What is a proxy pool and how it operates
- Core benefits of using proxy pools
- Quality considerations and proxy pool management
- Types of proxy pools and typical use cases
- Implementing proxy pools effectively in your projects
- My take on proxy pools after years of real-world use
- Hydraproxy’s proxy pool solutions
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Proxy pool defined | A proxy pool is a managed collection of IPs that rotate automatically to prevent detection and bans. |
| Quality beats quantity | IP quality and routing strategy matter more than pool size for defeating modern bot detection. |
| Rotation strategy is critical | Per-request rotation fits stateless scraping; sticky sessions support multi-step workflows needing session continuity. |
| Security risks in free pools | Free proxies lack encryption and expose users to man-in-the-middle attacks and data theft. |
| Match proxy type to task | Residential proxies work best for protected sites; datacenter proxies suit speed-focused, lower-risk tasks. |
What is a proxy pool and how it operates
A proxy pool is a collection of proxy servers managed as a single resource, where incoming requests are distributed across multiple IP addresses automatically. You don’t manage each IP manually. Instead, you connect to a single gateway endpoint, and the system handles IP selection and rotation transparently on the provider side. This architecture is what separates a proxy pool from simply having a list of proxies.
The fundamental reason proxy pools exist is scale and resilience. A single proxy IP will hit rate limits, get flagged, or get blocked after a limited number of requests to any given target. A proxy pool cycles through many IPs, so no single address takes enough traffic to trigger detection.
Proxy pools differ based on the type of IPs they contain:
- Residential proxies are IPs assigned by internet service providers to real home users. They carry the highest trust rating from target servers because they appear indistinguishable from regular user traffic.
- Datacenter proxies originate from cloud or hosting infrastructure. They’re faster and cheaper but easier for sites to identify as non-residential and block.
- Mobile proxies use IPs assigned by mobile carriers to 4G and 5G devices. Sites treat mobile IPs with high tolerance because blocking them risks blocking legitimate smartphone users.
Rotation strategy is the other core variable. Per-request rotation and sticky sessions serve different purposes. Per-request rotation assigns a new IP to every outbound request, which works well for stateless data collection tasks. Sticky sessions lock a specific IP for a configured time window, typically 30 seconds to 30 minutes, which is necessary when you need to maintain a login state or complete a multi-step checkout flow without breaking the session.
What is a rotating proxy within this context? A rotating proxy is any proxy that automatically switches the outgoing IP address, either per request or on a set schedule. In a proxy pool, every IP in the collection is a candidate for rotation. The pool manager selects which IP to assign based on factors like IP health, geographic target, and current load.
Core benefits of using proxy pools
The practical benefits of proxy pools break down into four categories, each with direct relevance to scraping, testing, and anonymity use cases.
- IP ban avoidance. A scraping job sending 100,000 requests per hour needs at least 1,000 IPs if the target site limits each IP to 100 requests per hour. Without a proxy pool, you either slow to a crawl or get banned. The pool distributes load so no single IP exceeds the rate threshold.
- Anonymity and privacy. Routing traffic through different IPs in a managed pool prevents any target server from building a persistent profile tied to a single address. This matters for competitive research, ad verification, and brand monitoring where you don’t want your traffic patterns attributed to your organization.
- Geo-targeting. Proxy pools with residential IPs across multiple countries let you access location-specific content, verify localized ad delivery, or compare pricing across regional markets. This is a core use case for travel fare aggregation and e-commerce price monitoring.
- Performance and load testing. Routing test traffic through multiple IPs simulates real-world latency variance and regional content delivery behavior. QA teams use proxy pools to run realistic load tests that reflect how different user populations actually reach a server.
Pro Tip: When using a proxy pool for geo-targeting, verify that the IPs in your pool are actually sourced from the target region. Some providers label IPs by region inaccurately. Test a sample against an IP geolocation service before running a full job.
Quality considerations and proxy pool management

The single biggest misconception about proxy pools is that more IPs automatically means better performance. In practice, IP quality and rotation strategy defeat advanced bot detection far more reliably than raw pool size. A pool of 10,000 low-quality, flagged IPs underperforms a well-managed pool of 1,000 clean residential IPs on any moderately protected site.
Effective proxy pool management uses a lifecycle model to keep the pool healthy. Here’s how a well-structured pool management process works:
- Health check. Each IP in the pool is tested against a set of target endpoints at regular intervals. Response time, success rate, and HTTP status codes are recorded.
- Active status. IPs passing health checks enter the active rotation pool and are assigned to outgoing requests.
- Quarantine. When an IP starts returning error responses or gets flagged by a target, it moves to quarantine. Without quarantine and revalidation, naive rotation repeatedly cycles through flagged IPs and increases detection risk across the entire pool.
- Cooldown and revalidation. After a cooldown period, quarantined IPs are retested. If they pass, they re-enter the active pool. If they fail repeatedly, they’re replaced.
- IP replacement. Permanently blocked or degraded IPs are cycled out and replaced with fresh addresses from the provider’s sourcing pipeline.
This lifecycle model is what separates professional proxy pool services from commodity IP lists. The management overhead is significant, which is why most serious operations use a managed provider rather than building internal infrastructure.
Pro Tip: If you’re building your own proxy pool, implement exponential backoff on quarantined IPs rather than a fixed cooldown timer. IPs blocked for aggressive scraping behavior recover faster when they’re rested longer on first offense.
Security is also a non-negotiable consideration. Free proxies often lack encryption and expose users to man-in-the-middle attacks, cookie theft, and session logging. For any workflow involving authenticated sessions or proprietary data, a secure proxy provider with documented sourcing and no-log policies is the only practical choice.
Types of proxy pools and typical use cases
Not all proxy pools serve the same purpose. The type of IP in the pool determines its trust level, cost, and suitability for different tasks.
| Proxy type | Cost | Detectability | Best use case |
|---|---|---|---|
| Residential | High | Low | Scraping protected sites, ad verification, geo-targeting |
| Datacenter | Low | High | High-speed data collection from unprotected sources |
| Mobile (4G/5G) | Highest | Very low | Social media automation, high-trust access tasks |
| ISP (static residential) | Medium-high | Low | Tasks needing consistent identity with residential trust |
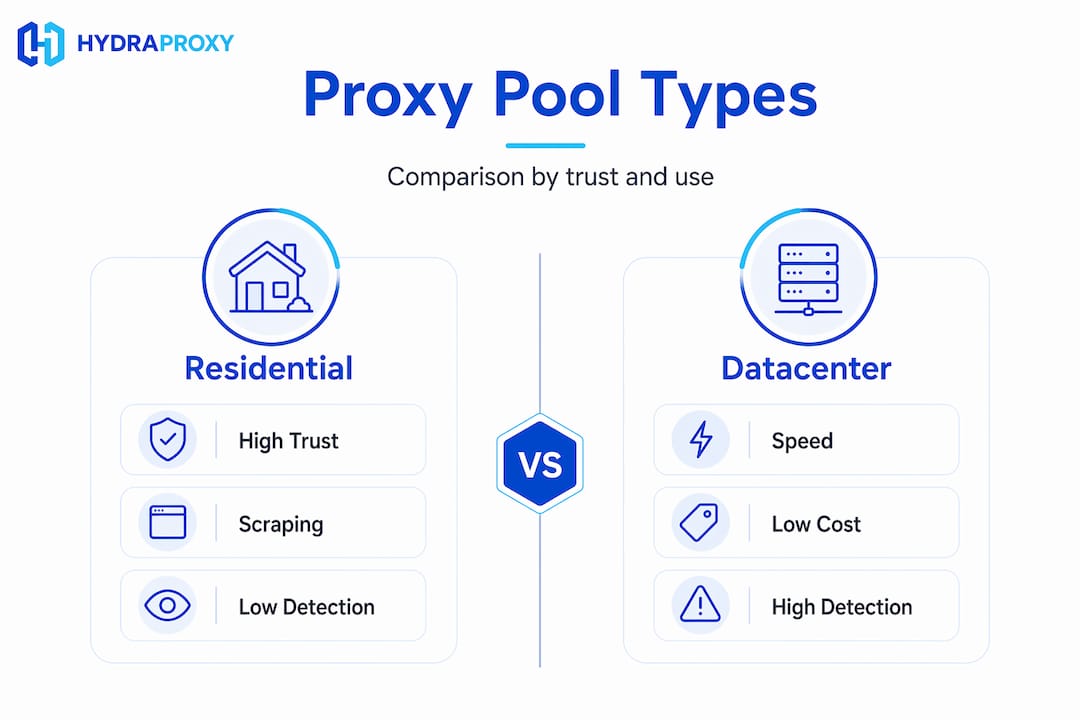
Residential proxies mimic real home users, making them the most reliable option for scraping complex sites with active anti-bot systems. They cost more per GB but deliver higher success rates where it counts. If you’re pulling pricing data from major retail platforms or verifying ad placements across geos, residential is the default choice.
Datacenter proxies make sense when the target site doesn’t run aggressive bot detection and throughput speed is the priority. Pulling data from open APIs, public data repositories, or less-protected directories are appropriate tasks for datacenter pools.
Mobile proxies occupy the highest trust tier. Because mobile carrier IPs serve millions of legitimate smartphone users, blocking a mobile IP range carries collateral damage risk for the blocking site. This makes mobile proxy infrastructure particularly effective for platforms with strict residential-only policies.
For application testing, ISP proxies, which are datacenter-hosted IPs that carry residential ISP assignments, provide a consistent IP identity with residential-level trust. QA teams use them for app testing and QA workflows where session consistency matters but pure residential pools would add unnecessary cost.
Implementing proxy pools effectively in your projects
Getting a proxy pool working is straightforward. Using it well requires deliberate configuration decisions before you write a single line of scraping logic.
- Use a single gateway endpoint. Most managed proxy pool providers give you one endpoint address. Rotation and IP selection happen on the provider side. You don’t need to manage an IP list in your code. This design also means connection pooling reduces per-request overhead because the client reuses the same TCP connection to the gateway while the backend cycles IPs.
- Set rotation policy based on workflow type. For stateless data collection, per-request rotation is appropriate. For workflows involving authentication, cart operations, or paginated sessions, configure sticky sessions with a duration that matches your expected session length.
- Respect rate limits per IP, not per pool. A proxy pool distributes requests, but if your request rate is so high that individual IPs still exceed target site thresholds, the pool won’t protect you. Calculate your per-IP request rate as total requests divided by active pool size.
- Monitor success rates continuously. Track HTTP 200 vs. block responses (403, 429, CAPTCHA pages) per job. A success rate drop is the earliest signal of pool degradation or a change in the target site’s detection logic.
- Separate pools by use case. Don’t use the same IP pool for high-volume scraping and account management tasks. Scraping generates the pattern signatures most likely to get IPs flagged. Mixing use cases contaminates pool health. You can learn more about this in Hydraproxy’s guide on proxies for data research and automation.
One often overlooked constraint is that rate limits tied to API credentials or authentication keys can cap your throughput regardless of how many IPs you rotate. If the target service rate-limits by account rather than IP, scaling the proxy pool alone won’t help. You need to address the credential layer separately.
My take on proxy pools after years of real-world use
I’ve worked with proxy pools long enough to have made most of the common mistakes personally. The one that costs teams the most time and money is treating pool size as the primary metric. I’ve seen operations spend significantly on 50,000-IP pools that consistently underperform because the IPs were poorly sourced, the rotation logic was naive, and nobody was monitoring IP health.
What I’ve learned is that a well-managed pool of 2,000 clean residential IPs with proper quarantine cycling will outperform a bloated pool of stale addresses on virtually every protected target. The management layer is what you’re actually paying for with a quality provider.
My other strong opinion is on free proxies. I’ve tested free proxy lists extensively. The security risks, specifically the logging and man-in-the-middle exposure, make them inappropriate for any serious workflow. The trade-offs between free and paid services are not subtle. Free pools fail under load, expose your data, and introduce reliability problems that corrupt your output without warning.
The last thing I’d tell anyone starting with proxy pools is this: your rotation strategy matters as much as your IP source. Per-request rotation for stateless collection, sticky sessions for anything with state. Get that decision right before you optimize anything else.
— Eduard
Hydraproxy’s proxy pool solutions
Hydraproxy operates premium residential and mobile proxy networks with active pool management, built for exactly the use cases covered in this article. Their infrastructure includes millions of residential IPs across global locations, with support for both per-request rotation and configurable sticky sessions. Pool health, IP sourcing quality, and ban recovery are managed at the infrastructure level, so you focus on your data tasks rather than IP lifecycle maintenance. If you’re ready to run reliable scraping, testing, or anonymity workflows without building pool management from scratch, start with Hydraproxy’s residential proxy network or explore the full proxy services platform to find the right proxy type for your project.
FAQ
What is a proxy pool in simple terms?
A proxy pool is a managed set of proxy IP addresses that rotate automatically to prevent any single IP from being detected or blocked by target websites.
How do proxy pools work technically?
You connect to a single gateway endpoint, and the proxy pool provider handles IP selection and rotation on the backend. Your requests go out through different IPs without any manual configuration on your side.
What is a rotating proxy and how is it different from a static proxy?
A rotating proxy automatically changes the outgoing IP address per request or on a schedule, while a static proxy always uses the same IP. Rotating proxies are the standard approach inside proxy pools for scraping and anonymity tasks.
Why is proxy pool quality more important than size?
IP quality and routing strategy defeat bot detection more reliably than raw IP count. A large pool of flagged or low-quality IPs still fails against sites with active anti-bot systems.
Are free proxy pools safe to use?
No. Free proxies often lack encryption and expose users to man-in-the-middle attacks, cookie theft, and session logging, making them unsuitable for any sensitive or production workflow.